Disclaimer: Coding Dojo cannot guarantee employment, salary, or career advancement. The experience of this alumnus/alumna may not be representative of all students. Pre-Dojo: Worked in a UPS warehouse and did...

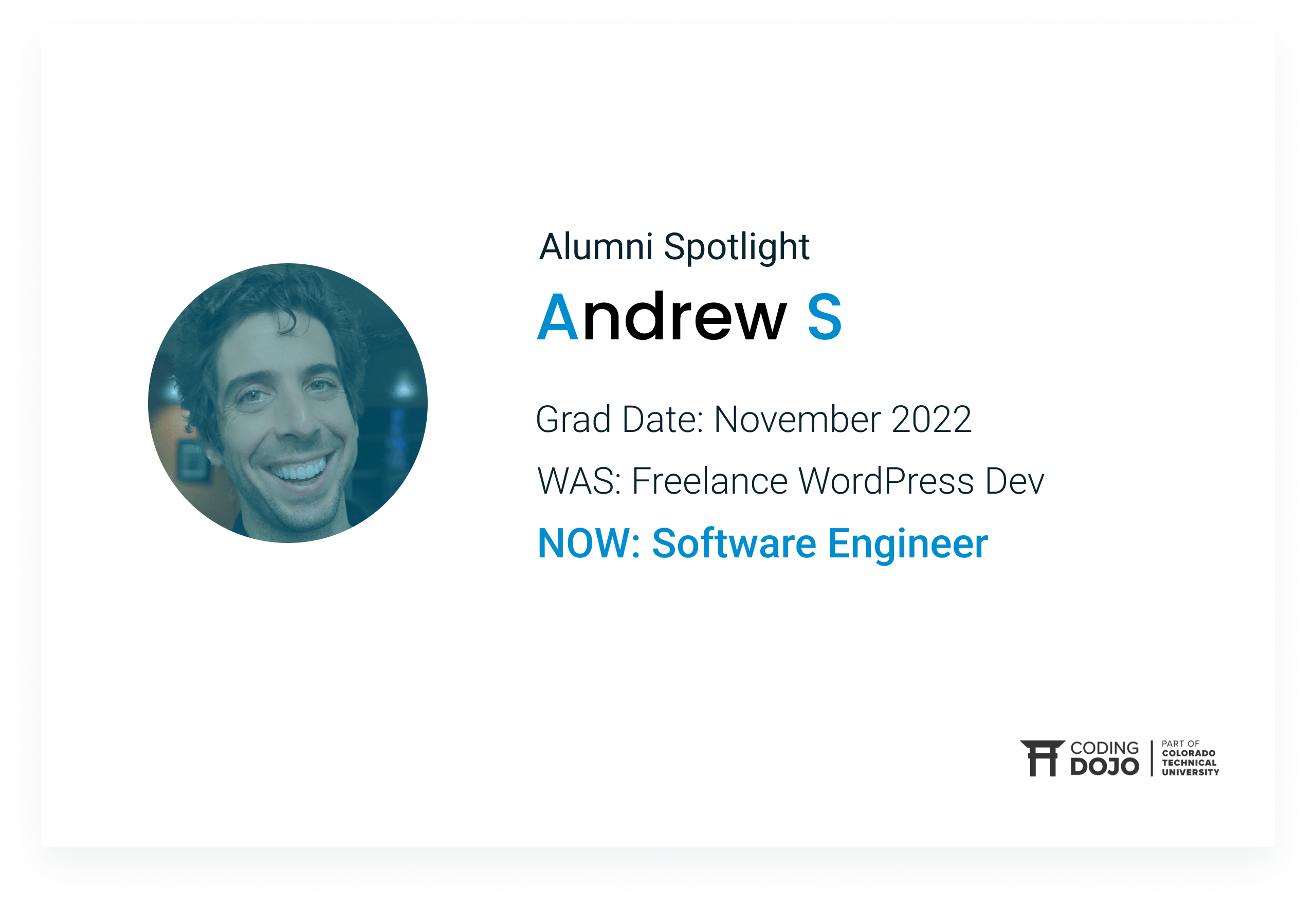
Alumni Andrew S accelerated his career path from a freelance WordPress dev to a Software Engineer thanks to the skills he learned at Coding Dojo.

Alumni Johann S went from being a high school graduate to a software engineer thanks to the skills he learned at Coding Dojo.

Disclaimer: Coding Dojo cannot guarantee employment, salary, or career advancement. The experience of this alumnus/alumna may not be representative of all students. Pre-Dojo: Worked as a bar back at...

Disclaimer: Coding Dojo cannot guarantee employment, salary, or career advancement. The experience of this alumnus/alumna may not be representative of all students. Pre-Dojo: Worked as a Network Administrator Grew...

Disclaimer: Coding Dojo cannot guarantee employment, salary, or career advancement. The experience of this alumnus/alumna may not be representative of all students. Pre-Dojo: Worked as a part-time orchestra teacher at...
Disclaimer: Coding Dojo cannot guarantee employment, salary, or career advancement. The experience of this alumnus/alumna may not be representative of all students. Pre-Dojo: Worked in a UPS warehouse and did audio engineering side jobs Discovered his love of coding while attending community college Wanted to accelerate his learning path into...
Alumni Andrew S accelerated his career path from a freelance WordPress dev to a Software Engineer thanks to the skills he learned at Coding Dojo.
Alumni Johann S went from being a high school graduate to a software engineer thanks to the skills he learned at Coding Dojo.
Disclaimer: Coding Dojo cannot guarantee employment, salary, or career advancement. The experience of this alumnus/alumna may not be representative of all students. Pre-Dojo: Worked as a bar back at a local arcade Was tired of pursuing industries and jobs he wasn't passionate about Wanted to find a career where...
Disclaimer: Coding Dojo cannot guarantee employment, salary, or career advancement. The experience of this alumnus/alumna may not be representative of all students. Pre-Dojo: Worked as a Network Administrator Grew up in Nigeria and moved to the U.S. two years ago Did not enjoy her job and wanted something better...
Disclaimer: Coding Dojo cannot guarantee employment, salary, or career advancement. The experience of this alumnus/alumna may not be representative of all students. Pre-Dojo: Worked as a part-time orchestra teacher at a public middle school, business owner and private teacher of her own private studio, and as a gig musician Felt...

